
昨日の夕方、Google はプレゼンテーションを行いました 拡散ジェマ、実験的なオープンソース モデル (Apache 2.0 ライセンスの下でリリース) で、テキスト生成への超高速アプローチで「テキストの拡散を探求」します。
この新しいモデルは、4 月初めに発表された Gemma 4 の 26B MoE モデルに基づいており、「従来の」大規模言語モデルの単純な逐次処理 (トークンごと) をさらに進化させ、テキストのブロック全体を同時に生成し、GPU でのテキスト生成が最大 4 倍高速になります。
Google Discover で Apple Geek LABO をフォローする
Google が DiffusionGemma を発表
当初の予想通り、Google はテキストの「普及」のための新しい実験的なオープンソース モデルを提示しました。 拡散ジェマ、速度を大幅に向上させ、従来の単語ごとの回答生成 (トークンごとの処理による) を超えることで、テキスト生成に革命を起こすことを目的としたモデルです。
当社の最新のオープン実験モデルは、専用 GPU で最大 4 倍高速な推論を実現し、速度が重要なインタラクティブなローカル ワークフローの探索への扉を開きます。
このモデルは、Gemma 4 ファミリの最も先進的なバージョンに基づいています (月初めに、12B モデル (おそらく Googlebooks に統合されるモデル) とスマートフォンと PC 用に最適化された QAT モデルで拡張されました)。
拡散ジェマ 生成速度を最大化するように設計されています。「自己回帰」Gemma 4 モデル (より伝統的なモデル) が高品質の結果の標準であり続けていますが、新しいモデルは、速度が重要なワークフロー (インライン編集、高速反復、非線形構造のテキストの生成) を模索する研究者や開発者向けに特別に作成されています。
ローカルで使用するためのアドホック モデル
開発者にとっての潜在的な利点に進む前に、効率に関する従来のモデルと普及モデルの違いについて簡単に説明し、Google が専用のブログ投稿で説明した内容を要約します。 拡散ジェマ。
これまでのところ、ほとんどの「従来の」言語モデルは一種のタイプライターとして機能し、一度に 1 つの「トークン」を左から右に生成してきました。これはクラウド操作では効率的ですが (サーバーはハードウェア負荷を分散することで数千のリクエストをグループ化できるため)、ローカルで実行される操作では AI 操作専用の GPU または TPU が適切に活用されていないため、同じことは起こりません。
マウンテンビューの巨人によると、 拡散ジェマ は、単語を順番に予測するのではなく、同時に 256 個のトークンから段落全体を作成するため、状況を逆転させることができます。したがって、PC のリソースは、ウィンドウごとに 1 つのトークンで実行できるよりも明らかに広範囲に活用されます。一方で、クラウドで使用すると、収益の減少やサービスコストの増加などのデメリットが生じる可能性があります。
テキスト拡散は基本的に AI ベースの画像生成と同様に機能します。モデルは静的なビジュアルから開始され、鮮明な画像が得られるまで繰り返し改良されます。このため、Google はこの原則をテキスト生成に適用し、ほぼリアルタイム、あるいはそれを超えたコードの生成とレンダリングへの扉を開こうと考えました。
本質的には、 拡散ジェマ それは、「ランダムな」プレースホルダーとしてそこに配置されたトークンで構成される「キャンバス」から始まります。この時点で、モデルは、正しいトークンをブロックし、残りを洗練するための「コンテキスト」として使用する、いくつかのステップに及ぶ反復的な改良を続けます。パスの終端に到達すると、モデルは最後のリビジョン (「最終改良」フェーズ) に進み、生成されたすべてのテキストが 1 つの出力に収束します。
Telegram で Google をフォローして、ニュースやオファーを最初に受け取りましょう
開発者にとって約束されたメリットは何ですか
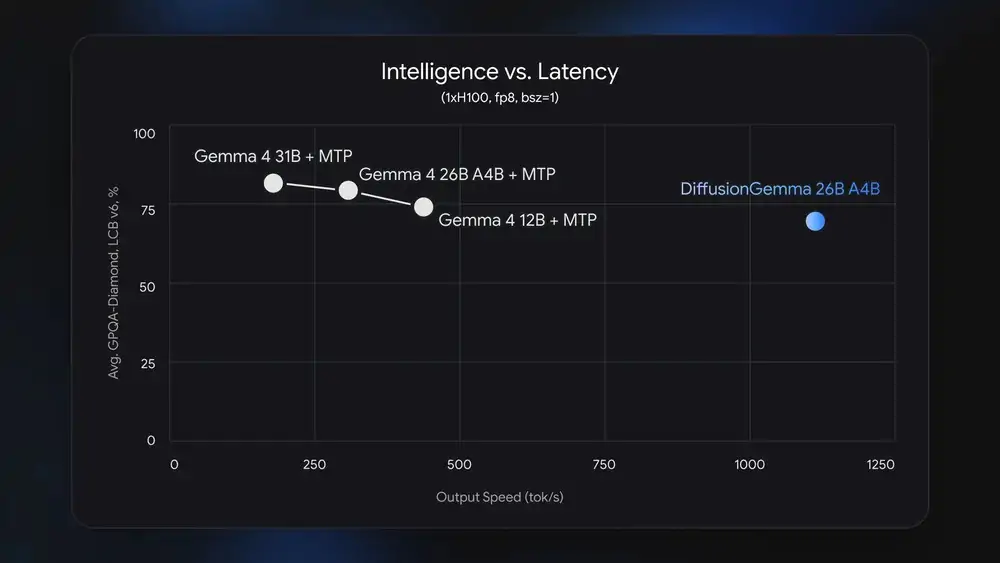
の有用性に戻ると、 拡散ジェマ、予想通り、このモデルは、速度にとって重要なワークフロー (インライン編集、高速反復、非線形構造によるテキスト生成)、つまり本当のボトルネックであるローカル推論レイテンシーに苦戦することが多いリアルタイム インタラクティブ アプリケーションを検討する研究者や開発者向けに設計されています。この意味で、モデルは次のようになります。
- デコードのボトルネックをメモリ帯域幅から実際の計算に移し、専用 GPU で最大 4 倍高速なトークン出力を生成します。
- これは 260 億パラメータの MoE モデルとして動作しますが、ハイエンドの専用コンシューマ GPU の VRAM 制限 (18GB) に対応するため、推論中にアクティブ化されるパラメータは 38 億のみです。
- 各フォワードパスと並行して 256 個のトークンを生成することで、各トークンが他のすべてのトークン (コンテキストとなる) に「注意を払う」ことができ、非線形領域 (インライン編集、コードの作成、アミノ酸配列、数学的グラフ) で大きな利点が得られます。
- 出力を繰り返し改良し、リアルタイムでエラーを修正できます。
- 速度と並列レイアウト生成を優先します。その結果、生成品質は標準の Gemma 4 モデルよりも低くなります。開発者の優先事項が最高の品質である場合に推奨されます。

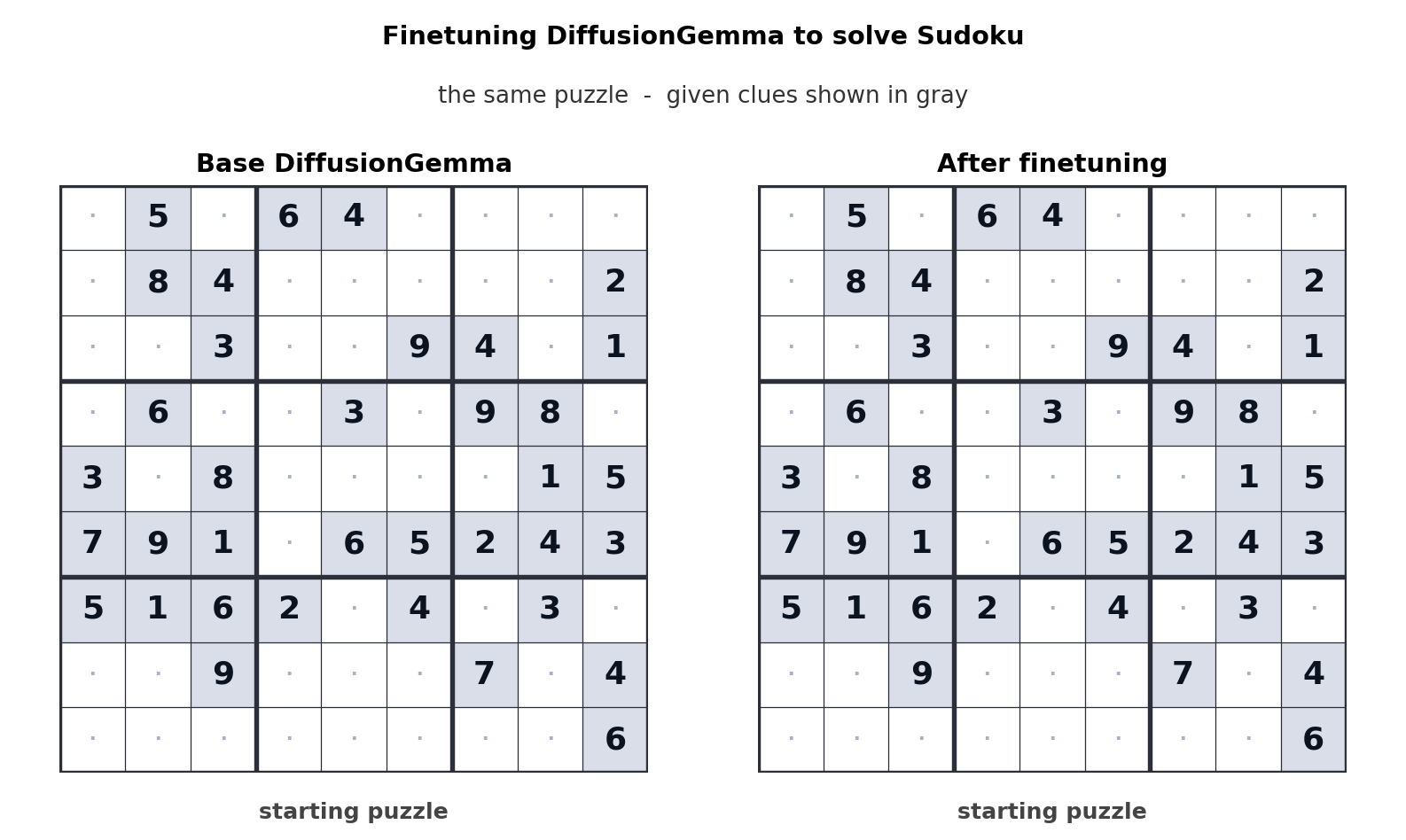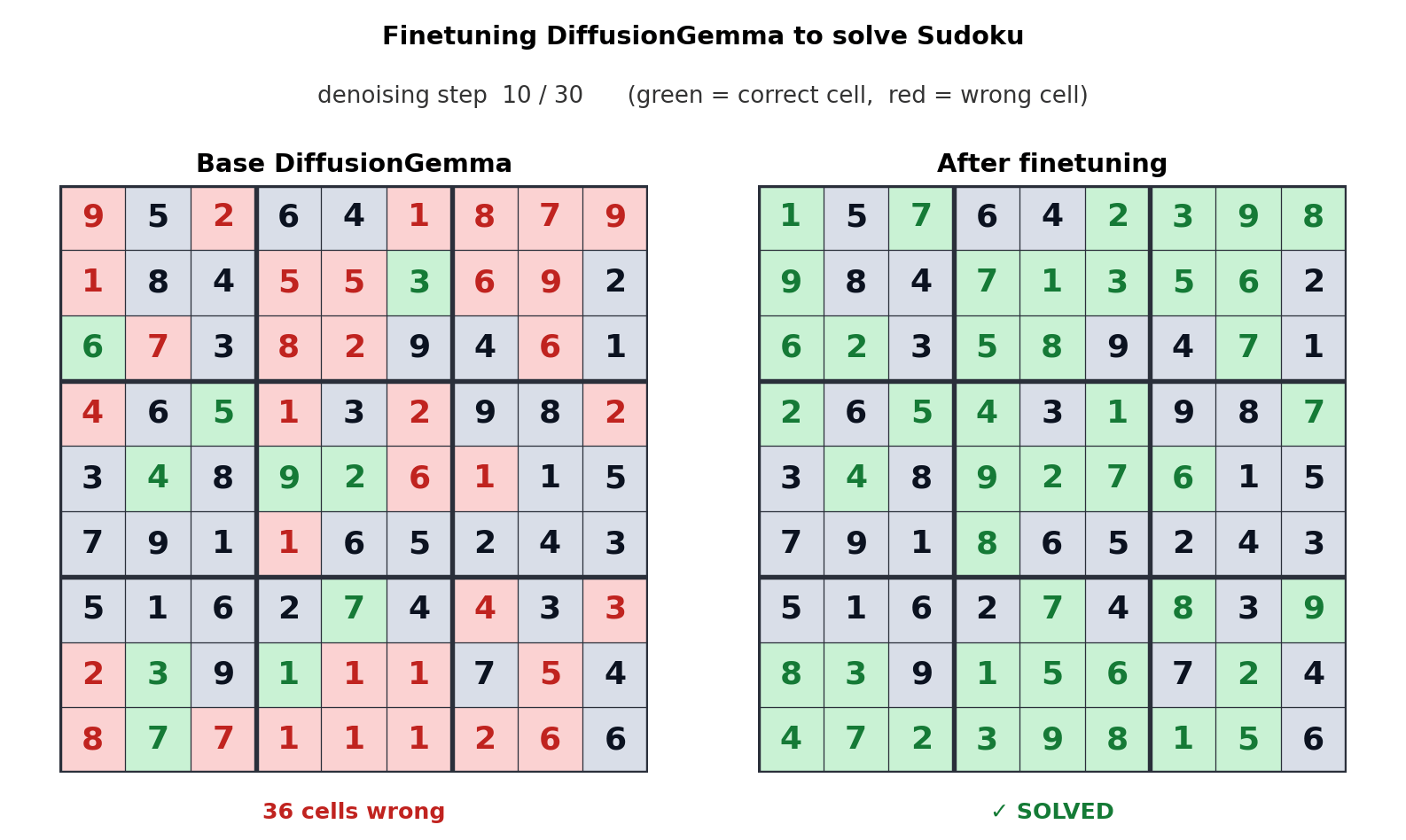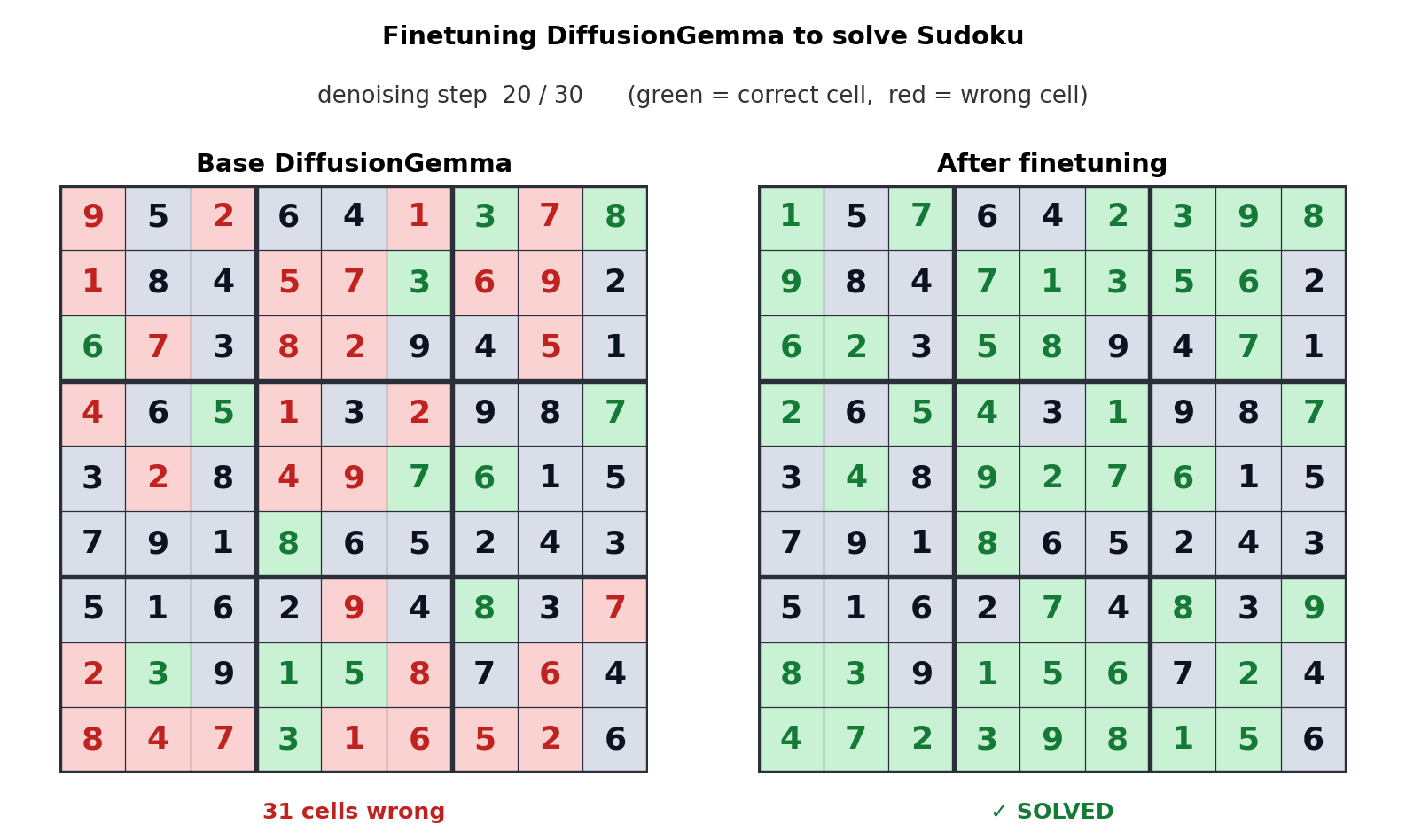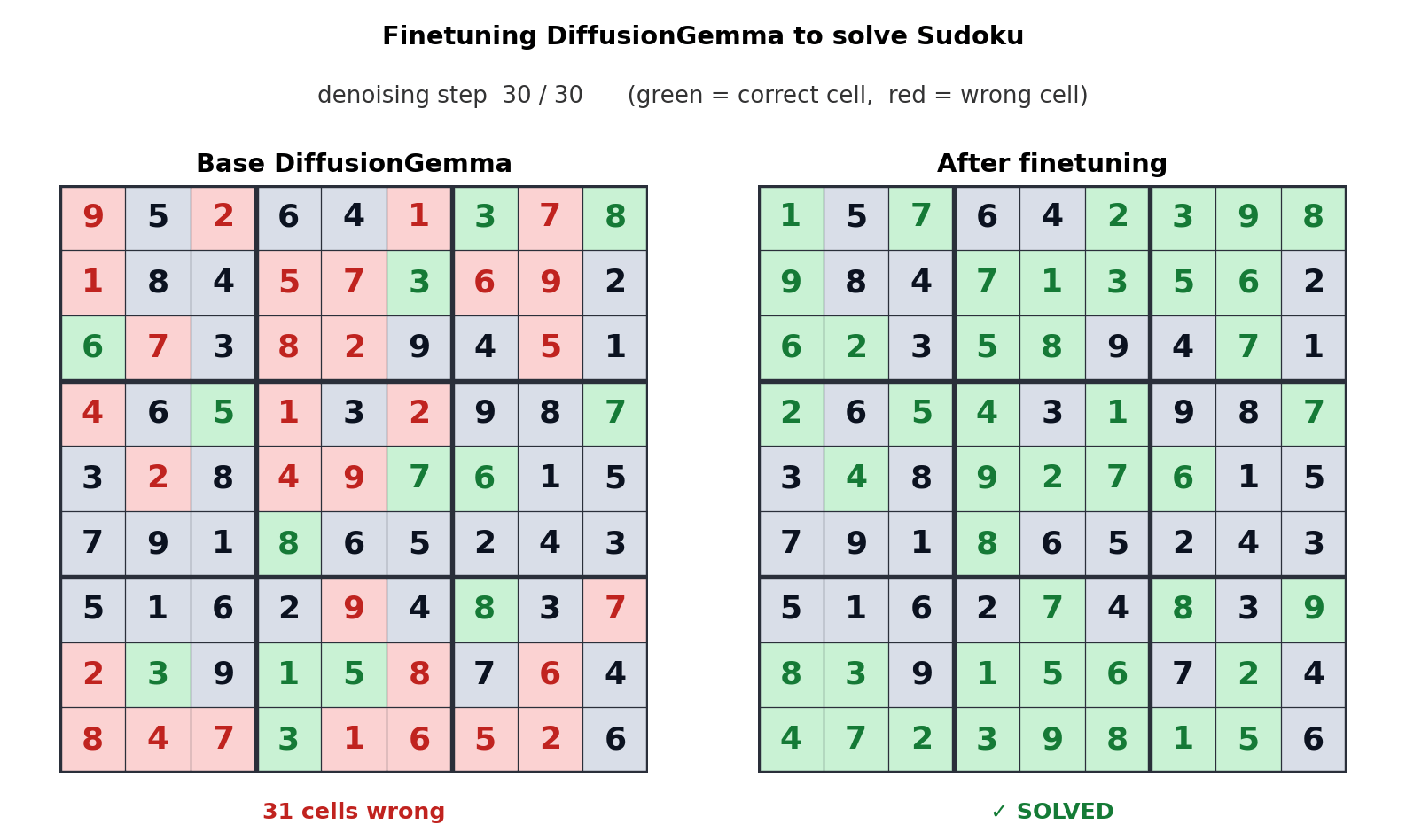
その後、Google は、パフォーマンスを向上させることが可能であることを知らせます。 拡散ジェマ 「微調整」を通じて特定のタスクを実行します。次の GIF は、「基本」バージョンのモデルと、数独をプレイするために最適化されたモデルの違いを示しています。
ご覧のとおり、最適化されたモデルでは、数独を解くのにわずか 5 つの手しかかかりません。ただし、基本モデルでは 30 の手ではそれを解決できません。
DiffusionGemma はすでに開発者によって使用可能です
新しいモデル 拡散ジェマ これは、HuggingFace で (Apache 2.0 ライセンスで予想されるように) オープン ソース形式ですでに入手可能であり、詳細については、Google が開発した開発者ガイドとビジュアル ガイドで提供されています。
このモデルは、MLX、vLLM (Red Hat によってサポートされる統合)、および Hugging Face Transformers を使用して効率的に実行できます。 Unsloth と NVIDIA NeMo を使用した Hackable Diffusion の微調整チュートリアルもあります。
パフォーマンスの面では、Google は NVIDIA と緊密に連携してハードウェア スタック全体が最適化され、「コンシューマ」構成 (RTX 5090 および 4090) との互換性と、NVIDIA DGX Spark や DGX Station などのエンタープライズ システムでの最大のパフォーマンスを確保しました。